Масштабирование
Управляемый Postgres предлагает гибкие варианты масштабирования под требования ваших рабочих нагрузок. Более 50 типов экземпляров на базе NVMe позволяют независимо масштабировать CPU, память и хранилище, оптимизируя производительность и стоимость под ваш конкретный сценарий использования.
Типы инстансов и гибкость
Managed Postgres предлагает широкий выбор типов инстансов, каждый из которых оптимизирован под разные характеристики рабочих нагрузок:
- Более 50 типов инстансов с конфигурациями, оптимизированными под вычислительные ресурсы, память и хранилище
- Хранилище на базе NVMe во всех типах инстансов для стабильного и высокопроизводительного дискового I/O
- Независимое масштабирование ресурсов: выбирайте оптимальное соотношение CPU, памяти и хранилища в зависимости от вашей нагрузки
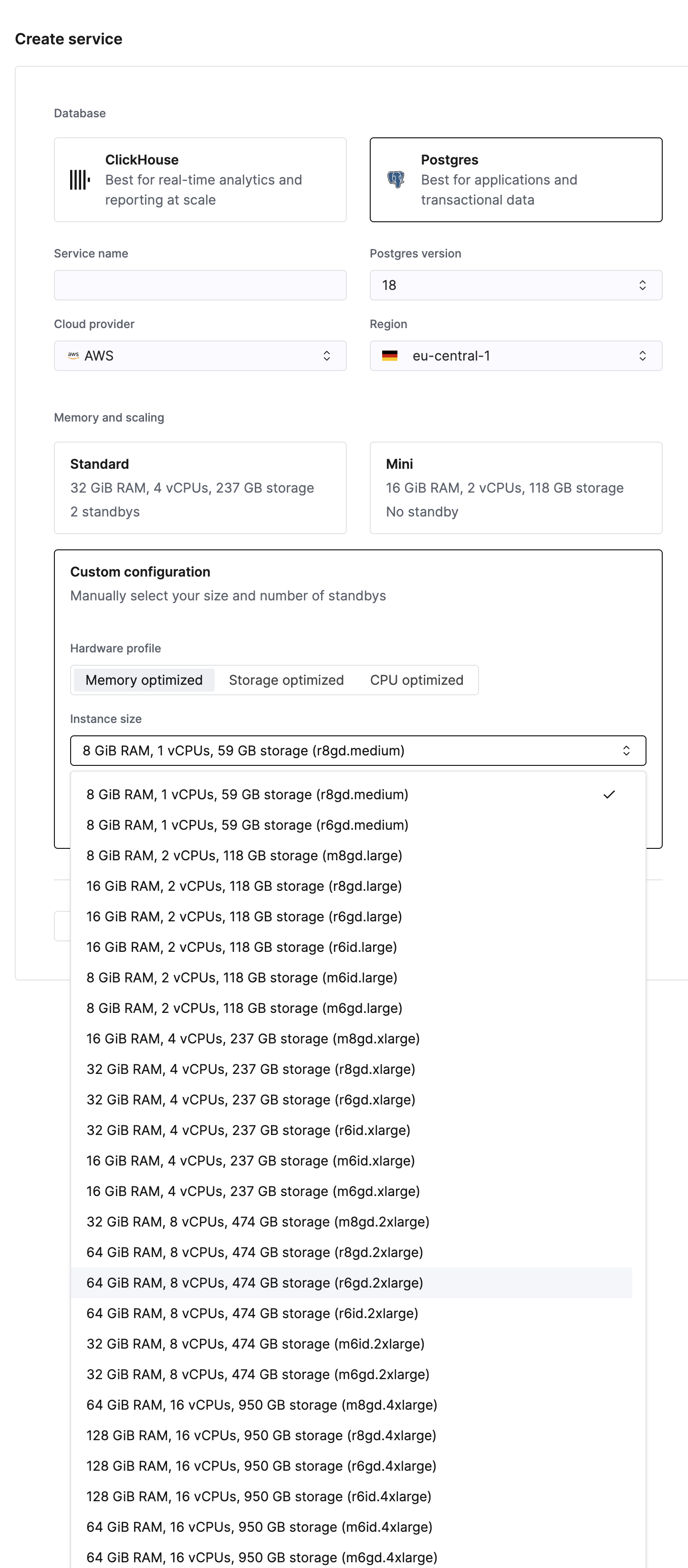
Выбор подходящего типа инстанса
Разные типы рабочих нагрузок требуют разных конфигураций ресурсов:
| Тип рабочей нагрузки | CPU | Память | Хранилище | Рекомендуемый тип инстанса |
|---|---|---|---|---|
| Оптимизированный под вычисления | Высокий | Средний | Средний | Оптимизированный под вычисления (много vCPU) |
| Оптимизированный по памяти (большой рабочий набор данных) | Средний | Высокий | Средний | Оптимизированный по памяти (высокое соотношение память/CPU) |
| Оптимизированный по хранилищу (большие наборы данных, высокая I/O-нагрузка) | Средний | Средний | Высокий | Оптимизированный по хранилищу (большая ёмкость NVMe) |
Как работает масштабирование
Когда вы изменяете тип экземпляра, Managed Postgres выполняет вертикальное масштабирование, при котором создаётся новая инфраструктура и с минимальным простоем переносится ваша база данных.
Процесс масштабирования
Процесс масштабирования поднимает новый standby из резервных копий и выполняет управляемый failover:
-
Подготовка standby: создаётся новый экземпляр standby с целевым типом инстанса (конфигурацией CPU, памяти и хранилища).
-
Восстановление из резервных копий в S3: standby инициализируется путём восстановления из самой свежей резервной копии, сохранённой в S3.
-
Параллельное проигрывание WAL: standby применяет все изменения Write-Ahead Log (WAL), произошедшие после момента создания резервной копии, используя параллельные механизмы восстановления на базе WAL-G:
- WAL-G обеспечивает быстрые, параллельные операции восстановления;
- создатель WAL-G входит в команду Ubicloud, с которой мы сотрудничаем, что обеспечивает глубокую экспертизу и оптимизацию.
-
Синхронизация репликации: standby догоняет primary за счёт потоковой передачи и применения текущих изменений WAL.
-
Failover: после полной синхронизации standby управляемый failover повышает standby до роли нового primary:
- это единственный шаг, который вызывает простой (~30 секунд);
- все активные подключения прерываются во время failover;
- клиентам необходимо переподключиться после завершения failover.
-
Вывод старого экземпляра из эксплуатации: исходный экземпляр выводится из эксплуатации после завершения failover.
Длительность масштабирования
Общее время, необходимое для масштабирования, в первую очередь зависит от размера вашей базы данных и объема WAL-данных, которые нужно воспроизвести из резервных копий:
- Восстановление резервной копии: время, необходимое для восстановления самой свежей полной резервной копии из S3 на новый инстанс
- Воспроизведение WAL: время для применения инкрементальных изменений WAL, накопившихся с момента последней полной резервной копии
- Параллельное восстановление: механизмы параллельного восстановления WAL-G значительно ускоряют процесс
Время восстановления может варьироваться от нескольких минут до нескольких часов, но простой (окно обслуживания) при этом крайне мал — всего около 30 секунд.
Ваше приложение будет недоступно примерно 30 секунд во время переключения (failover), независимо от того, сколько времени занимает весь процесс масштабирования. Все операции по восстановлению и выравниванию состояния выполняются в фоновом режиме на резервном инстансе.
Параллельное восстановление с WAL-G
Managed Postgres использует WAL-G для ускорения восстановления из резервных копий во время операций масштабирования. Важно отметить, что создатель WAL-G входит в команду Ubicloud, с которой мы сотрудничаем, что привносит глубокую экспертизу в процесс восстановления.
WAL-G обеспечивает:
- Параллельную загрузку и декомпрессию: Несколько сегментов резервной копии загружаются из S3 и декомпрессируются одновременно
- Эффективное применение WAL: Инкрементальные изменения WAL применяются параллельно, где это возможно
- Оптимизированную потоковую передачу: Непосредственная потоковая передача из хранилища S3 без промежуточного копирования
- Быстрое восстановление: Хотя общее время зависит от объема данных, параллельный подход делает процесс достаточно быстрым
Эти оптимизации значительно сокращают время, необходимое для запуска нового standby-экземпляра. Что особенно важно, восстановление полностью выполняется в фоновом режиме — ваше приложение испытывает простой только в течение короткого окна переключения (failover) продолжительностью примерно 30 секунд.
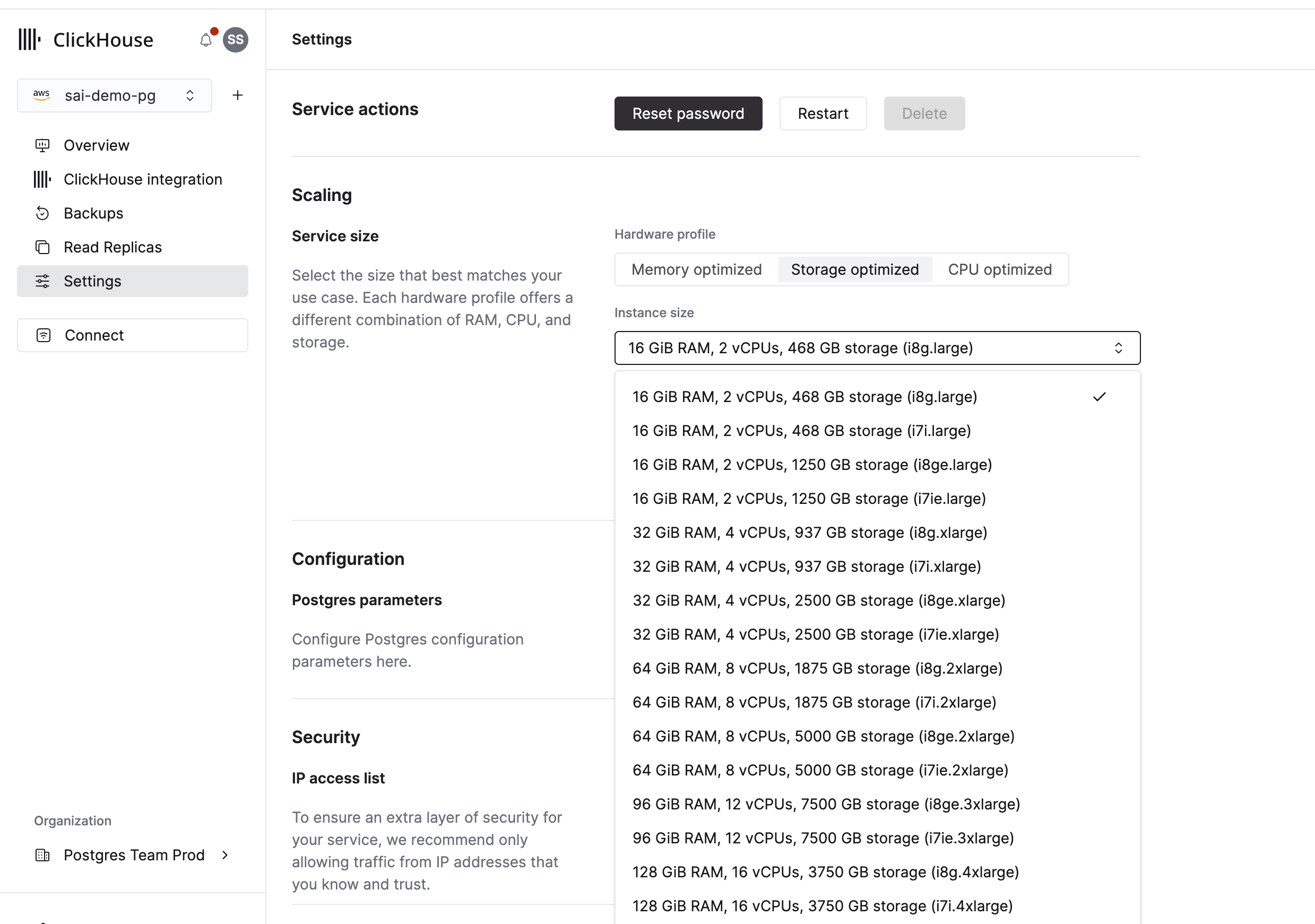
Запуск операции масштабирования
Чтобы масштабировать ваш экземпляр Managed Postgres:
- Перейдите на вкладку Settings вашего экземпляра
- В разделе Scaling прокрутите до Service size
- Выберите целевой тип экземпляра
- Просмотрите изменения и нажмите кнопку Apply changes
Стратегии масштабирования
Вертикальное масштабирование
Вертикальное масштабирование (изменение типов экземпляров) — основной метод настройки ресурсов в Managed Postgres. Этот подход обеспечивает:
- Точное управление: Выбирайте из более чем 50 типов экземпляров, чтобы точно настроить CPU, память и хранилище
- Оптимизацию нагрузки: Подбирайте конфигурации, оптимизированные под вашу конкретную нагрузку (ресурсоёмкую по вычислениям, памяти или хранилищу)
- Экономическую эффективность: Платите только за нужные ресурсы без избыточного выделения ресурсов
Реплики для чтения для горизонтального масштабирования
Для нагрузок, в которых преобладают операции чтения, рассмотрите возможность использования реплик для чтения для горизонтального масштабирования пропускной способности чтения:
- Снимайте нагрузку с основного кластера, перенаправляя запросы на выделенные экземпляры реплик для чтения
- Каждая реплика для чтения — это полностью независимый экземпляр Postgres со своими собственными вычислительными ресурсами и памятью
- Реплики для чтения потоково считывают изменения WAL из объектного хранилища для эффективной репликации
Этот подход оптимален для приложений с высокой долей операций чтения по сравнению с записью, таких как отчётные панели, аналитические запросы или API с интенсивными операциями чтения.
Масштабирование CDC для интеграции с ClickHouse
Если вы выполняете репликацию данных в ClickHouse с помощью ClickPipes, вы можете независимо масштабировать конвейер CDC (фиксация изменений данных):
- Масштабируйте воркеры CDC от 1 до 24 ядер CPU
- Объём памяти автоматически масштабируется до значения, равного 4× количеству ядер CPU
- Настраивайте масштабирование через ClickPipes OpenAPI
Это позволяет оптимизировать пропускную способность репликации независимо от ресурсов экземпляра Postgres.
Автомасштабирование
При заполнении диска на 90% тип вашего инстанса будет автоматически изменён на более крупный.
